# 介绍
范式(NormalForm): 设计数据库时,需要遵循的一些规范。各种范式呈递次规范,越高的范式数据库冗余越小
# 第一范式(1NF)
每一列都是不可分割的原子数据项,错误案例:
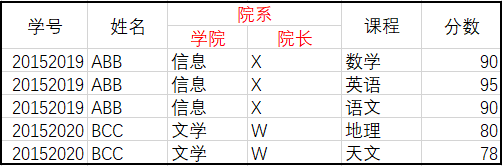
# 存在的问题
- 存在非常严重的数据冗余
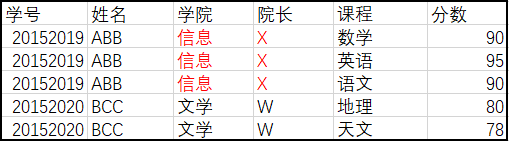
- 数据添加存在问题,例如添加新学院
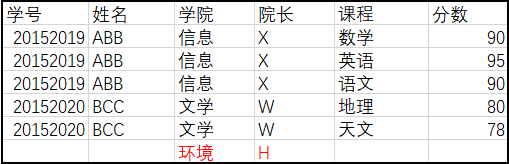
- 数据删除存在问题,例如删除学生可能导致学院也从表中被删除
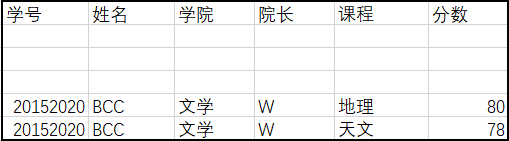
# 第二范式(2NF)
在第一范式的基础上,非码属性必须完全依赖于码(在第一范式基础上消除部分依赖)
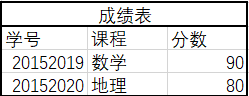
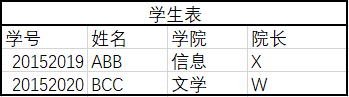
解决了数据冗余的问题,但是依然有数据添加和删除的问题
# 基本概念
函数依赖: A->B 如果通过A属性(或属性组)的值,可以唯一确定B属性的值,则称B依赖于A
例如: 学号->姓名,(学号,课程)->分数(属性组)
完全函数依赖: A->B 如果A是一个属性组,B属性值的确定需要依赖A属性组中所有的属性值
例如: (学号,课程)->分数
部分函数依赖: A->B 如果A是一个属性组,B属性值的确定只需要依赖于A属性组中某一些值即可
例如: (学号,课程)->姓名
传递函数依赖: A->B, B->C 如果B依赖于A,C依赖于B,则称C传递函数依赖于A
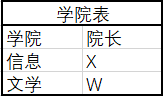
例如: 学号->学院,学院->院长
码: 在一张表中,如果一个属性(属性组),被其他所有属性所依赖,则称这个属性(属性组)为该表的码
例如: 学生表中的码为 (学号,课程)
主/非主属性: 码属性组中的所有属性即主属性,码属性组外的属性为非主属性
# 第三范式(3NF)
在第二范式的基础上,任何非主属性不依赖于其他非主属性(在第二范式基础上消除传递依赖)
消除: 学号->学院,学院->院长(注意,下例中学生表并没有完全消除)
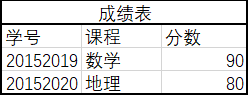
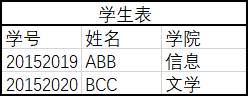
← 数据库设计-多表间关系 多表查询 →